5.1 스프링 부트 소개
스프링 부트는 스프링에서 파생된 여러 서브 프로젝트에서 시작해서 메인 프로젝트가 되어버린 케이스입니다. 스프링 부트의 중요한 특징으로 Auto Configuration(자동 설정)을 내세울 수 있습니다. 예를 들어 데이터베이스와 관련된 모듈을 추가하면 자동으로 데이터베이스 관련 설정을 찾아서 실행합니다. 다른 특징으로는 내장 톰캣과 단독 실행 가능한 도구라는 것입니다. 별도의 서버 설정 없이도 개발이 가능하고 실행이 가능합니다.
서블릿에서 스프링으로 넘어오는 과정은 기존의 코드를 재활용할 수 없기 때문에 러닝커브가 상당히 큰 편이었습니다. 반면 스프링에서 스프링 부트로 넘어오는 일은 기존 코드나 개념이 그대로 유지되기 때문에 뭔가 새로운 개념이 필요하지는 않습니다.
필요한 라이브러리를 기존 build.gradle 파일에 추가하는 설정이 상당히 단순하기도 하지만 자동으로 처리됩니다. 특히 톰캣이 내장된 상태로 프로젝트가 생성되기 때문에 WAS의 추가 설정이 필요하지 않다는 점도 편리합니다.
스프링 MVC에서는 JSP를 이용할 수는 있지만 스프링 부트는 Thymeleaf라는 템플릿 엔진을 활용하는 경우가 많습니다.
스프링부트의 프로젝트 생성 방식
크게 2가지로 볼 수 있습니다.
1. Spring Initializr를 이용한 자동 생성
2. Maven이나 Gradle을 이용한 직접 생성
Spring Data JPA를 위한 설정
spring.jpa.hibernate.ddl-auto 속성은 프로젝트 실행 시 DDL 문을 처리할 것인지를 명시합니다. 송성값은 다음과 같이 지정 가능합니다.
| 속성값 | 의미 |
| none | DDL을 하지 않음 |
| create-drop | 실행할 때 DDL을 실행하고 종료 시에 만들어진 테이블 등을 모두 삭제 |
| create | 실행할 때마다 새롭게 테이블을 생성 |
| update | 기존과 다르게 변경된 부분이 있을 때는 새로 생성 |
| validate | 변경된 부분만 알려주고 종료 |
JSON 데이터 만들기
API 서버는 JSP나 THYMELEAF처럼 서버에서 화면과 관련된 내용을 만들어 내는 것이 아니라 순수한 데이터만 전송하는 방식입니다.
JSON은 'JavaScript Object Notation'의 약자로 구조를 가진 데이터를 자바스크립트의 객체 표기법으로 표현한 순수한 문자열입니다. 문자열이기 때문에 데이터 교환시에 프로그램 언어에 독립적이라는 장점이 있습니다. (스프링을 이용할 때는 jackson-databind라는 별도의 라이브러리를 추가한 후에 개발할 수 있지만 스프링 부트는 web항목을 추가할 때 자동으로 포함됩니다)
@RestController
@Log4j2
public class SampleJSONController {
@GetMapping("/helloArr")
public String[] helloArr() {
log.info("helloArr");
return new String[]{"AAA", "BBB", "CCC"};
}
}
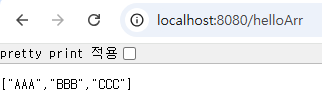
'/helloArr'경로를 호출하면 배열이 그대로 출력됩니다. 서버에서 해당 데이터는 'application/json'이라는 것을 전송했습니다.
5.2 Thymeleaf
Thymeleaf는 템플릿이기 때문에 JSP처럼 직접 데이터를 생성하지 않고 만들어진 결과에 데이터를 맞춰서 보여주는 방식입니다. JSP와 마찬가지로 서버에서 동작하기는 하지만 HTML을 기반으로 화면을 구성하기 때문에 HTML에 조금 더 가깝습니다.
출력
Thymeleaf는 Model로 전달된 데이터를 출력하기 위해서 HTML 태그 내에 'th:..'로 시작하는 속성을 이용하거나 inlining을 이용합니다.
@Controller
@Log4j2
public class SampleController {
@GetMapping("/hello")
public void hello(Model model) {
log.info("hello");
model.addAttribute("msg","Hello World");
}
@GetMapping("/ex/ex1")
public void ex1(Model model) {
List<String> list = Arrays.asList("AAA","BBB", "CCC", "DDD");
model.addAttribute("list", list);
}
}<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<h4>[[${list}]]</h4>
<hr/>
<h4 th:text="${list}"></h4>
</body>
</html>
프로젝트를 실행하고 '/ex/ex1'을 호출하면 사진과 같은 결과가 나옵니다.
주석 처리
에러가 발생하게 되면 원인을 찾아내기 힘듭니다. 에러가 난 부분을 찾기 위해서 주석 처리를 할 때는'<!--/* ... */-->'를 이용하는 것이 좋습니다.
th:with를 이용한 변수 선언
임시로 변수를 선언해야 하는 상황에서는 'th:with'를 이용해서 간단히 처리할 수 있씁니다. '변수명 = 값'의 형태로 ','를 이용해서 여러 개를 선언할 수도 있습니다.
반복문과 제어문
반복문 처리는 크게 2가지 방법을 이용할 수 있습니다.
- 반복이 필요한 태그에 'th:each'를 적용하는 방법
- <th:block>이라는 별도의 태그를 이용하는 방법
'th:each' 속성을 이용할 때는 기존의 HTML을 그대로 둔 상태에서 반복 처리를 할 수 있다는 장점이 있지만 JSTL과는 조금 이질적인 형태이고 <th:block>을 이용할 때는 추가로 태그가 들어간다는 단점이 있습니다.
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<ul>
<li th:each="str: ${list}" th:text="${str}"></li>
</ul>
<ul>
<th:block th:each="str: ${list}">
<li>[[${str}]]</li>
</th:block>
</ul>
</body>
</html>
반복문의 status 변수
th:each를 처리할 때 현재 반복문의 내부 상태에서 변수를 추가해서 사용할 수 있습니다. 일명 status 변수라고 하는데 index/count/size/first/last/odd/even 등을 이용해서 자주 사용하는 값들을 출력할 수 있습니다.
status 변수명은 사용자가 지정할 수 있고 index는 0부터 시작하는 번호를 의미합니다.
th:if / th:unless / th: switch
제어문의 형태로 th:if / th:unless / th: switch를 이용할 수 있습니다.
th:if 와 th:unless 는 사실상 별도의 속성으로 사용할 수 있으므로 if~else와는 조금 다르게 사용됩니다.
<ul>
<li th:each="str,status: &{list}">
<span th:if="${status.odd}"> ODD --[[${str}]]</span>
<span th:unless="${status.odd}"> EVEN --[[${str}]]</span>
</li>
</ul>
?를 이용하여 이항 혹은 삼항 처리가 가능합니다.
<ul>
<li th:each="str,status: &{list}">
<span th:text="${status.odd} ?'ODD ---'+${str}"></span>
</li>
</ul>
th:switch는 th:case와 같이 사용해서 Switch문을 처리할 때 사용할 수 있습니다.
<ul>
<li th:each="str,status: &{list}">
<th:block th:switch= "${status.index % 3}">
<span th:case="0">0</span>
<span th:case="1">1</span>
<span th:case="2">2</span>
</th:block>
</li>
</ul>
Thymeleaf 링크 처리
'@'로 링크를 작성하기만 하면 됩니다.
<a th:href="@{/hello}">Go to /hello</a>
링크를 key=value의 형태로 필요한 파라미터를 처리해야 할 떄 편리합니다. 쿼리스트링은 '()'를 이용해서 파라미터의 이름과 값을 지정합니다.
<a th:href="@{/hello(name='AAA' , age=1 6)}">Go to /hello</a>
인라인 처리
인라인: 동일한 데이터를 다르게 출력해주는 기능
레이아웃 기능
<th:block>을 이용하면 레이아웃을 만들고 특정한 페이지에서는 필요한 부분만을 작성하는 방식으로 개발이 가능합니다.
5-3 Spring Data JPA
JPA는 (Java Persistence API)라는 기술을 간단하게 '자바로 영속 영역을 처리하는 API'라고 해석할 수 있습니다. JPA의 상위 개념은 ORM(Object Relational Mapping)이라는 패러다임으로 이어지는데 이는 '객체지향'으로 구성한 시스템을 '관계형 데이터베이스'에 매핑하는 패러다임입니다.
JPA는 스프링과 연동할 떄 Spring Data JPA라는 라이브러리를 사용합니다. Spring Data JPA는 JPA를 단독으로 활용할 때 보다 더 적은 양의 코드로 많은 기능을 활용할 수 있다는 장점이 있습니다.
Board 엔티티와 JpaRepository
JPA를 이용하는 개발의 핵심은 객체지향을 통해서 영속 계층을 처리하는 데 있습니다. JPA를 이용할 때는 SQL을 다루는 것이 아니라 데이터에 해당하는 객체를 엔티티 객체라는 것으로 다루고 JPA로 이를 데이터베이스와 연동해서 관리하게 됩니다.
엔티티 객체: PK를 가지는 자바의 객체. 고유의 식벽을 위해 @ID를 이용해서 구분하고 관리합니다.
Spring Data JPA는 자동으로 객체를 생성하고 이를 통해서 예외 처리 등을 자동으로 처리하는데 이를 위해서 제공되는 인터페이스가 JpaRepository입니다.
개발의 첫 단계는 엔티티 객체를 생성하기 위한 엔티티 클래스를 정의하는 것입니다.
@Entity
public class Board {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long bno;
private String title;
private String content;
private String writer;
}
엔티티 클래스는 반드시 @Entity가 존재하고 엔티티 객체의 구분을 위한 @ID가 필요합니다.
키 생성 전략
- IDENTITY: 데이터베이스에 위임(MYSQL/MariaDB) - auto_increment
- SEQUENCE: 데이터베이스 시퀀스 오브젝트 사용(ORACLE)-@SequenceGenerator 필요
- TABLE: 키 생성용 테이블 사용, 모든 DB에서 사용-@TableGenerator 필요
- AUTO: 방언에 따라 자동 지정, 기본값
방언: 데이터베이스가 제공하는 문법과 함수의 차이
- JPA는 종속되지 않은 추상화된 방언 클래스를 제공하여 시간과 비용을 아낄 수 있습니다.
MappedSuperClass를 이용한 공통 속성 처리
데이터베이스의 대부분의 테이블에는 데이터가 추가된 시간이나 수정된 시간 등이 칼럼으로 작성됩니다. 이를 쉽게 처리하고자 @MappedSuperClass를 이용해서 공통으로 사용되는 칼럼들을 지정하고 해당 클래스를 상속해서 손쉽게 처리합니다.
@MappedSuperclass
@EntityListeners(value={AuditingEntityListener.class})
@Getter
public class BaseEntity {
@CreatedDate
@Column(name= "regdate", updatable = false)
private LocalDateTime regdate;
@LastModifiedDate
@Column(name="moddate")
private LocalDateTime moddate;
}AuditingEntityListener: 엔티티가 데이터베이스에 추가되거나 변경될 때 자동으로 시간 값을 지정할 수 있습니다. 활성화 시키기 위해서는 프로젝트의 설정에 @EnableJpaAuditing을 추가해 주어야 합니다.
@SpringBootApplication
@EnableJpaAuditing
public class B01Application {
public static void main(String[] args) {
SpringApplication.run(B01Application.class, args);
}
}@Entity
@Getter
@Builder
@AllArgsConstructor
@NoArgsConstructor
@ToString
public class Board extends BaseEntity{
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long bno;
@Column(length = 500, nullable = false) //칼럼의 길이와 null허용여부
private String title;
@Column(length = 2000, nullable = false)
private String content;
@Column(length = 50, nullable = false)
private String writer;
}BaseEntity를 상속하도록 변경하고 어노테이션을 추가했습니다.
JpaRepository 인터페이스
JpaRepository라는 인터페이스를 이용해서 인터페이스 선언만으로 데이터베이스 관련 작업을 어느 정도 처리할 수 있습니다. JpaRepository인터페이스를 상속하는 인터페이스를 선언하는 것만으로 CRUD와 페이징 처리가 모두 완료됩니다.
public interface BoardRepository extends JpaRepository<Board, Long> {
}
JpaRepository 인터페이스를 상속할 때는 엔티티 타입과 @Id 타입을 지정해주어야 하는 점을 제외하면 아무런 코드 없이도 개발이 가능합니다.
테스트 코드를 통한 CRUD/페이징 처리 확인
insert
JpaRepository의 save()를 통해서 이루어 집니다. 현재의 영속 컨텍스트 내에 데이터가 존재하는지 찾아보고 해당 엔티티 객체가 없을 때는 insert를, 존재할 때는 update를 자동으로 실행합니다.
@Test
public void testInsert(){
IntStream.rangeClosed(1,100).forEach(i ->{
Board board = Board.builder()
.title("title..." +i)
.content("content..."+ i)
.writer("user"+(i%10))
.build();
Board result=boardRepository.save(board);
log.info("BNO: "+result.getBno());
});
}
select
특정한 번호의 게시물을 조회하는 기능은 findByID()를 이용해서 처리합니다. findByID()의 리턴 타입은 Optional<T>입니다.
@Test
public void testSelect(){
Long bno=100L;
Optional<Board> result=boardRepository.findById(bno);
Board board = result.orElseThrow();
log.info(board);
}update
insert와 동일하게 save()를 통해서 처리됩니다. 동일한 @ID값을 가지는 객체를 생성해서 처리할 수 있습니다. update는 등록 시간이 필요하므로 가능하면 findByID()로 가져온 객체를 이용해서 약간의 수정을 통해서 처리하는 것이 좋습니다.
엔티티 객체는 최소한의 변경이나 변경이 없는 불변(immutable)하게 설계하는 것이 좋습니다.
@Test
public void testUpdate(){
Long bno=100L;
Optional<Board> result=boardRepository.findById(bno);
Board board = result.orElseThrow();
board.change("update..title 100", "update content 100");
boardRepository.save(board);
}
}delete
@ID에 해당하는 값으로 deleteByID()를 통해서 실행할 수 있습니다. 내부에 같은 @ID가 존재하는지 먼저 확인하고 delete문이 실행됩니다.
@Test
public void testDelete(){
Long bno=1L;
boardRepository.deleteById(bno);
}
Pageable과 Page<E>타입
페이징 처리는 Pageable이라는 타입의 객체를 구성해서 파라미터로 전달하면 됩니다. Pageable은 인터페이스로 설계되어 있고 PageRequest.of()라는 기능을 이용해서 개발이 가능합니다.
- PageRequest.of(페이지 번호, 사이즈): 페이지 번호는 0부터
- PageRequest.of(페이지 번호, 사이즈, sort): 정렬 조건 추가
- PageRequest.of(페이지 번호, 사이즈, Sort.Direction, 속성..): 정렬 방향과 여러 속성 지정
파라미터로 Pageable을 이용하면 리턴 타입은 Page<T>타입을 이용할 수 있는데 이는 단순 목록뿐 아니라 페이징 처리에 데이터가 많은 경우에는 count 처리를 자동으로 실행합니다. 대부분의 Pageable 파라미터는 메소드 마지막에 사용하고 파라미터에 Pageable이 있는 경우에는 메소드의 리턴 타입을 Page<T>타입으로 설계합니다.
findAll()이라는 기능을 제공하여 기본적인 페이징 처리를 지원합니다. findall()의 리턴 타입으로 나오는 Page<T>타입은 내부적으로 페이징에 처리에 필요한 여러 정보를 처리합니다.(다음 페이지가 존재하는지, 이전 페이지가 존재하는지 등)
쿼리 메소드와 @Query
쿼리 메소도는 보통 SQL에서 사용하는 키워드와 칼럼을 같이 결합해서 구성하면 그 자체가 JPA에서 사용하는 쿼리가 되는 기능입니다. 일반적으로 메소드 이름은 'findBy...' 혹은 'get...'으로 시작하며 칼럼명과 키워드를 결합하는 방식으로 구성합니다. 사용하려면 상당히 길고 복잡한 메소드를 작성하게 되는 경우가 많아 단순한 쿼리를 작성할 때 사용하며 실제 개발에서는 많이 사용되지는 않습니다.
쿼리 메소드와 유사하게 별도의 처리 없이 @Query로 JPQL을 이용할 수 있습니다. @Query 어노테이션의 value로 작성하는 문자열을 JPQL이라고 하는데 SQL과 유사하게 JPA에서 사용하는 쿼리 언어라고 생각하면 됩니다. JPA는 데이터베이스에 독립적으로 개발이 가능하므로 특정한 데이터베이스에서만 동작하는 SQL대신에 JPA에 맞게 사용하는 JPQL을 이용하는 것입니다.
JPQL은 테이블 대신 엔티티 타입을 이용하며 칼럽 대신에 엔티티의 속성을 이용해서 작성합니다.
@Query를 이용하면 쿼리 메소드가 할 수 없는 몇가지 기능을 할 수 있습니다.
- 조인과 같이 복잡한 쿼리를 실행할 수 있는 기능
- 원하는 속성들만 추출해서 Object[]로 처리하거나 DTO로 처리하는 기능
- nativeQuery 속성값을 true로 지정해서 특정 데이터베이스에서 동작하는 SQL을 사용하는 기능
native 속성을 지정하는 예제는 다음과 같습니다.
@Query(value = "select now()" , nativeQuery = true)
String getTime();
Querydsl을 이용한 동적 쿼리 처리
데이터베이스를 이용해야 할 때 JAP나 JPQL을 이용하면 SQL을 작성하거나 쿼리를 처리하는 소스 부분이 줄어들어 편리하지만 어노테이션을 이용해 지정하기 때문에 고정된 형태라는 단점이 있습니다. 이러한 문제의 원인은 JPQL이 정적으로 고정되기 때문입니다. 이를 해결하기 위해 사용되는 방식이 Querydsl입니다. Querydsl을 이용하면 자바 코드를 이용하기 때문에 타입의 안정성을 유지한 상태에서 원하는 쿼리를 작성할 수 있습니다.
JPQLQuery는 @Query로 작성했던 JPQL을 코드를 통해서 생성할 수 있게 합니다. 이를 통해서 where이나 group by 혹은 조인 처리 등이 가능합니다. JPQL 실행은 fetch()라는 기능을 이용하며 fetchCount()를 이용하면 count 쿼리를 실행할 수 있습니다.
Pageable 처리
Querydsl의 실행 시에 Pageable을 처리하는 방법은 BoradSearchImpl이 상속한 QuerydslRepositorySupport라는 클래스의 기능을 이용합니다.
BooleanBuilder: 조건을 동적으로 생성하고 결합할 때 유용하게 사용됩니다. 주로 복잡한 조건문을 작성할 때 코드의 가독성을 높이고, 효율적으로 조건을 관리할 수 있게 도와줍니다.
기존의 Repository와 Querydsl 연동하기
- Querydsl을 이용할 인터페이스 선언
- 인터페이스 이름+impl 이라는 이름으로 클래스를 선언 -이때 QuerydslRepositorySupport라는 부모 클래스를 지정하고 인터페이스를 구현
- 기존의 Repository에는 부모 인터페이스로 Querydsl을 위한 인터페이스를 지정
public interface BoardSearch {
Page<Board> search1(Pageable pageable);
}public class BoardSearchImpl extends QuerydslRepositorySupport implements BoardSearch{
public BoardSearchImpl() {
super(Board.class);
}
@Override
public Page<Board> search1(Pageable pageable) {
return null;
}
}
실제 구현 클래스는 인터페이스 이름+Impl 로 작성합니다.
public interface BoardRepository extends JpaRepository<Board, Long>, BoardSearch {
@Query(value="select now()", nativeQuery = true)
String getTime();
}BoardRepository의 선언부에 BoardSearch 인터페이스를 추가로 지정합니다.
'자바웹개발 워크북' 카테고리의 다른 글
| 자바웹개발 워크북(7) (0) | 2025.01.20 |
|---|---|
| 자바웹개발 워크북(6) (1) | 2025.01.20 |
| 자바웹개발 워크북(4) (0) | 2025.01.05 |
| 자바웹개발 워크북(3) (0) | 2025.01.02 |
| 자바웹개발 워크북(2) (0) | 2025.01.01 |